Progress Update #2
April 26, 2019
Goals
Over the last two weeks I’ve set many goals to meet and encountered many difficulties in doing so. After the initial progress of the first week and its promising results; I felt very confident going into the next stage of the project. The first goal was to improve the performance of the model so enable a more complex one to be trained. This performance increase would come from GPU acceleration. After that was accomplished I would build and integrate a NEAT (neuroevolution of augmenting topology) and train it with evolutionary learning methods. To
-
Improve model performance with GPU acceleration
-
Use model performance to attain higher accuracy with full color images
-
Train model with increased performance and visualize results
GPU acceleration
Most modern computer systems come equipped with a graphics processing unit that is separate from all the other hardware in your computer but preforms a very important job. Your computers graphics require many millions of a very specific type of calculation, a type of calculation that your CPU can do, but is not purpose built for: matrix math. The basic principle is that matrix math is many small operations that can be done at the same time and dont rely on the result of another calculation. This allows GPUs to contain thousands of cores that function independently:
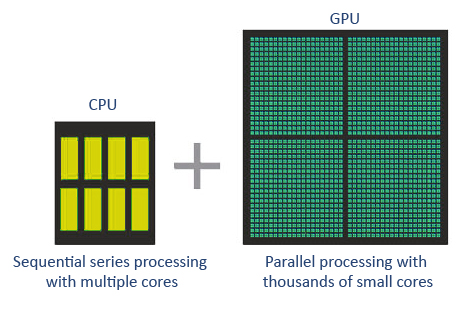
Matrix math turns out to be very useful for purposed besides graphics as well, machine learning models being one of them. As many models are structured as large matrix multiplication problems, using your computers GPU instead of the CPU could bring a large performance improvement with minimal change to your code.
With some persistence and initial frustration setting up the third party software for GPU integration, the training program ran with no errors, and the model that took over 6 hours to train previously, trained in less than 2 minutes.
Full color reconstruction
For simplicity, when I began building the auto encoder model, it was built to run off of gray scale images. But as a result of the conversion, much of the information in the image is lost (such as traffic light colors). Therefore to improve the information retention of the model it should be able to reconstruct full color images from the original while still achieving optimal compression.
While preserving the color of the images, here are some examples of the newly collected data set to get an idea of the environment the model will be trained in:

With the new data, the model would have to be adapted to accommodate for the extra dimension of color. This required the model structure be increased to three dimensional volumes instead of images:
Using this structure on an image would effectively reduce its size from 140000 values to a much more reasonable 1000 values while still being able to reconstruct fundamental details.

Controlling the environment
The model being used to control the vehicle has multiple moving parts and as such, there came challenges when attempting the integration of different software.
As an overview, the basic flow of information in the model will follow this pattern:

Communication from the learning model to the program takes place in three scenarios: the model receiving camera input, the model preforming determined actions, and attempt performance being extracted from the environment. Camera input is accomplished with a simple screencapture around the window of the simulation application and fed directly to the model input. To control the environment keystrokes are simulated to control the steering angle and pedal depressions of the vehicle. Lastly results are interpreted by a optical character recognition engine that extracts the position coordinates from the environment to be fed into evolutionary algorithm.
Updated results
Finally the results acheived after this week are an improvement upon the last, with full color images being compressed and reconstructed to a fair degree of detail where descisions can be made. The model compresses the original image by a factor of 140 while still being able to reconstruct it.

Conclusions
This weeks progress was another step in the right direction and I surpassed my original goals on the effectiveness of model I could acheive. With the images being compressed over 140 times smaller than the original, the final descision making policy will be significantly easier to deduce for the evolutionary algorithm which will be implemented next week.